It’s not a secret that most companies understand the importance of data. Data is a commodity that needs to be collected and cleaned by data engineering teams in a centralised store, commonly referred to as a Data Warehouse. Then, other roles or areas in the company will be using this data for common business needs to extract value in the form of decision making dashboards, mathematical models, predictive models or to feed machine learning algorithms among other things.
Hive is the first popular consumer solution to tackle the challenge of SQL to big data user in Apaches’ Hadoop ecosystem. In our data engineering team, we’ve been using Hive for our scheduled batches to process and collect data on a daily basis and store it in our centralised repository.
Hive excels in batch disc processing with a map reduce execution engine. Actually, Hive can also use Spark as its execution engine which also has a Hive context allowing us to query Hive tables.
Despite all the great things Hive can solve, this post is to talk about why we move our ETL’s to the ‘not so new’ player for batch processing, Spark. Spark is fast becoming the standard de facto in the Hadoop ecosystem for batch processing. If you’re reading this, you probably know about Hive and have heard of Spark. If this isn’t the case, don’t be afraid because I will introduce you to both technologies!
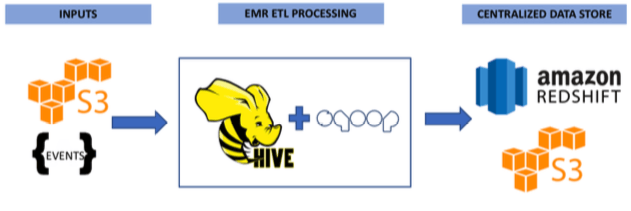
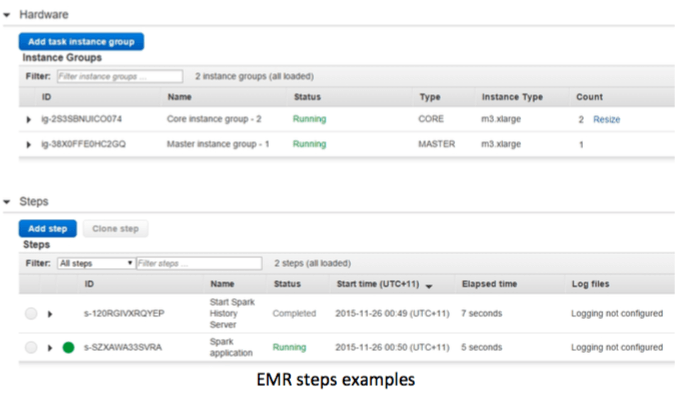
Our daily batch consists of EMR steps scheduled to run sequentially. For each step, we run HQL scripts that extract, transform and aggregate input event data into one Hive table result and we store it in HDFS.
$ hive -f filename.hql
Then we used SQOOP to load our centralised store, Redshift, with the Hive table previously created and stored in HDFS.
In my opinion some of the most important features in Hive are:
- HiveQL, it’s a declarative language that allows us to create a map reduce program with ease by only using our SQL skills, depending on the version you can have more options. The solution is still evolving.
- It’s well integrated with many technologies in the Hadoop Ecosystem such as HDFS and cloud Amazon services such as S3.
- It has impressive built in functions for reading different formats such as JSON, plain files etc.
- Apart from other advanced internals that is in charge of processing optimisation.
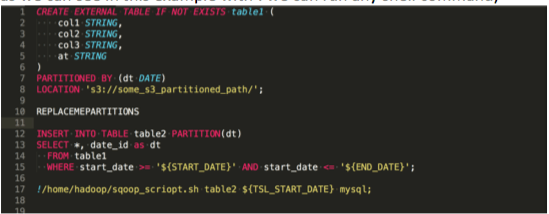
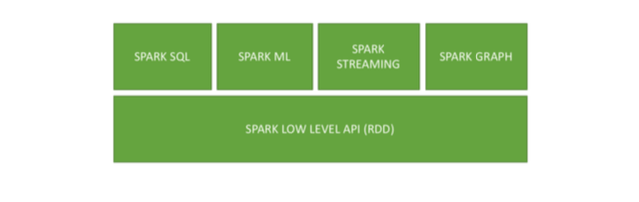
- HIn memory processing, Spark improves iterative computations.
- HAutomated Unit Testing capabilities.
- HCan natively read from many sources with ease (after version 2).
- HCan write to any JDBC source, AVRO, PARQUET or any raw file.
- HSupport Multiple languages, allowing users to create advanced and reusable projects.
- HA healthy and huge user community.
- HMajor Cloud Clustered computing vendors are supporting it as well, such as Amazon, Databricks, Google Cloud.
Before we could get started on the migration, we had a lot of decisions to make. Which Spark version? Which language, versions, testing libraries etc…
We started from apache Spark 2.0.0 the latest version available at the moment we started to migrate the existing Hive steps. Some would argue it’s not a good idea to use the latest version since it can bring some immature features that could break our processes. But our team has a different mindset, we think using the last “stable version” means that many features have been fixed, patched or improved.
As a programming language, we chose Scala because Spark was made with Scala. New features are always available in Scala initially (over other languages) and we are functional programmers therefore feel more comfortable with it.
Initially, the project we are using in our batch was created with IntelliJ and SBT, the version of SBT at the moment we started was 0.13 and the Scala version 2.11. IntelliJ is the community version, but I want to clarify that many of my teammates prefer to use different editors as VS Code, Sublime, Atom … So you can pick whichever you prefer.
Jupyter is another great alternative preferred by Python enthusiasts.

The folder structure in Scala Spark project looks like any standard Java Structure, something similar to this:
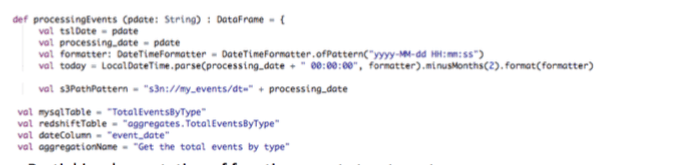
So most of our aggregations need to read from the same data JSON events, as in Hive, and generate new tables to be stored in our Redshift database or S3 or any other place we want to store our results.
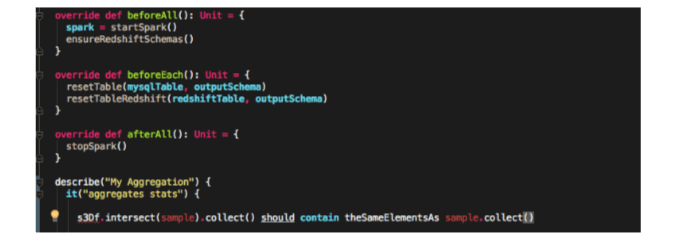
The main difference with Hive, is that, in Spark we can create tests and we should, so it’s obvious it’s not comparable. I won’t say that programming a test with Spark is very similar to any programming with a regular testing library in any popular language, but be aware it takes considerable execution time compared to regular testing.
Once we have migrated all steps, we noticed we reduced the execution time of our batch to more than 50% with the exact same hardware. Spark and Hive have different hardware needs.
We did some optimisation by using the Spark UI. Cache data frames in specific places also help to improve the performance of our jobs.
In some cases, we struggled with memory issues with Spark with no apparent solution apart from increasing the memory available in each node of the cluster. I mean, it’s supposed to be if the Spark process consumes all the memory it starts to spill to the disc but will continue processing data, but this is something that isn’t always the case, many times it breaks.
Tests are a bit painful since we have to generate fake data mocks for our tests and it cost time to create them.
In some cases it’s more natural and readable for most people to read plain SQL than read programmatic Spark, so we try (as much as we can) to use plain SQL and create a data frame or data set from it.
It’s also important to do as much work as you can in an external relational database engine so you only import the data needed.
It’s not easy to tune Spark and there is no one setting to fit all.
We want to create better and faster tests. We want to improve our Scala and Spark skills. We have started working with Spark streaming projects so we can get real-time data insights into life.
Personally, I’m very interested in machine learning, NPL, deep learning and I’m looking forward to working in conjunction with my (data) teammates to help to create awesome algorithms for recommendations, stats, better user experience etc…
Databricks Notebooks and their community cluster.
Supergloo contains a good free content with basic tutorials depending if your preference is python or Scala. You can find also some of this courses in Udemy.
Apache Spark 2.0 with Scala — Hands On with Big Data!
The book High performance Spark by Holden Karau and Rachel Warren, both are contributors of the Spark project.
We´ve gained a lot by migrating our old Hive aggregations into Spark. As I mentioned earlier Hive is a very robust technology, so your process can take time but they do complete most of the time. In Spark, you need a lot of memory resources to have a similar level of completeness.
It’s a bit complicated to tune Spark as there isn’t a configuration to fit all use cases.
Apart from those issues it’s really a pleasure to develop with Spark, you can use functional RDD’s, you can use high-level SQL, streaming and structured streaming in a super easy way, so I’m very glad to work with one of the leading data frameworks (of the moment).

